Pipeline Resources¶
It is very fast to iterate on a job's tasks by configuring them in the pipeline.yml YAML file. You edit the pipeline.yml, run fly set-pipeline, and the entire pipeline is updated automatically.
The initial lessons introduced Tasks as standalone YAML files (which can be run via fly execute). Our pipeline.yml YAML files can be refactored to use these.
Also in the earlier lesson Task Scripts we looked at extracting complex run commands into standalone shell scripts.
But with pipelines we now need to store the task file and task script somewhere outside of Concourse.
Concourse offers no services for storing/retrieving your data. No git repositories. No blobstores. No build numbers. Every input and output must be provided externally. Concourse calls them "Resources". Example resources are git, s3, and semver respectively.
See the Concourse documentation Resource Types for the list of built-in resource types and community resource types. Send messages to Slack. Bump a version number from 0.5.6 to 1.0.0. Create a ticket on Pivotal Tracker. It is all possible with Concourse resource types. The Concourse Tutorial's Miscellaneous section also introduces some commonly useful Resource Types.
The most common resource type to store our task files and task scripts is the git resource type. Perhaps your task files could be fetched via the s3 resource type from an AWS S3 file; or the archive resource type to extract them from a remote archive file. Or perhaps the task files could be pre-baked into the image_resource base Docker image. But mostly you will use a git resource in your pipeline to pull in your pipeline task files.
This tutorial's source repository is a Git repo, and it contains many task files (and their task scripts). For example, the original tutorials/basic/task-hello-world/task_hello_world.yml.
To pull in the Git repository, we edit pipeline-resources/pipeline.yml and add a top-level section resources:
resources:
- name: resource-tutorial
type: git
source:
uri: https://github.com/starkandwayne/concourse-tutorial.git
branch: develop
Next, add a get: resource-tutorial step, and update the task: hello-world step to replace the config: section with file: resource-tutorial/tutorials/basic/task-hello-world/task_hello_world.yml.
jobs:
- name: job-hello-world
public: true
plan:
- get: resource-tutorial
- task: hello-world
file: resource-tutorial/tutorials/basic/task-hello-world/task_hello_world.yml
To deploy this change:
cd ../pipeline-resources
fly -t tutorial set-pipeline -c pipeline.yml -p hello-world
fly -t tutorial unpause-pipeline -p hello-world
The output will show the delta between the two pipelines and request confirmation. Type y. If successful, it will show:
apply configuration? [yN]: y
configuration updated
The hello-world pipeline now shows an input resource resource-tutorial feeding into the job job-hello-world.
The Concourse Tutorial verbosely prefixes resource- to resource names, and job- to job names, to help you identify one versus the other whilst learning. Eventually you will know one from the other and can remove the extraneous text.
After manually triggering the job via the UI, the output will look like:
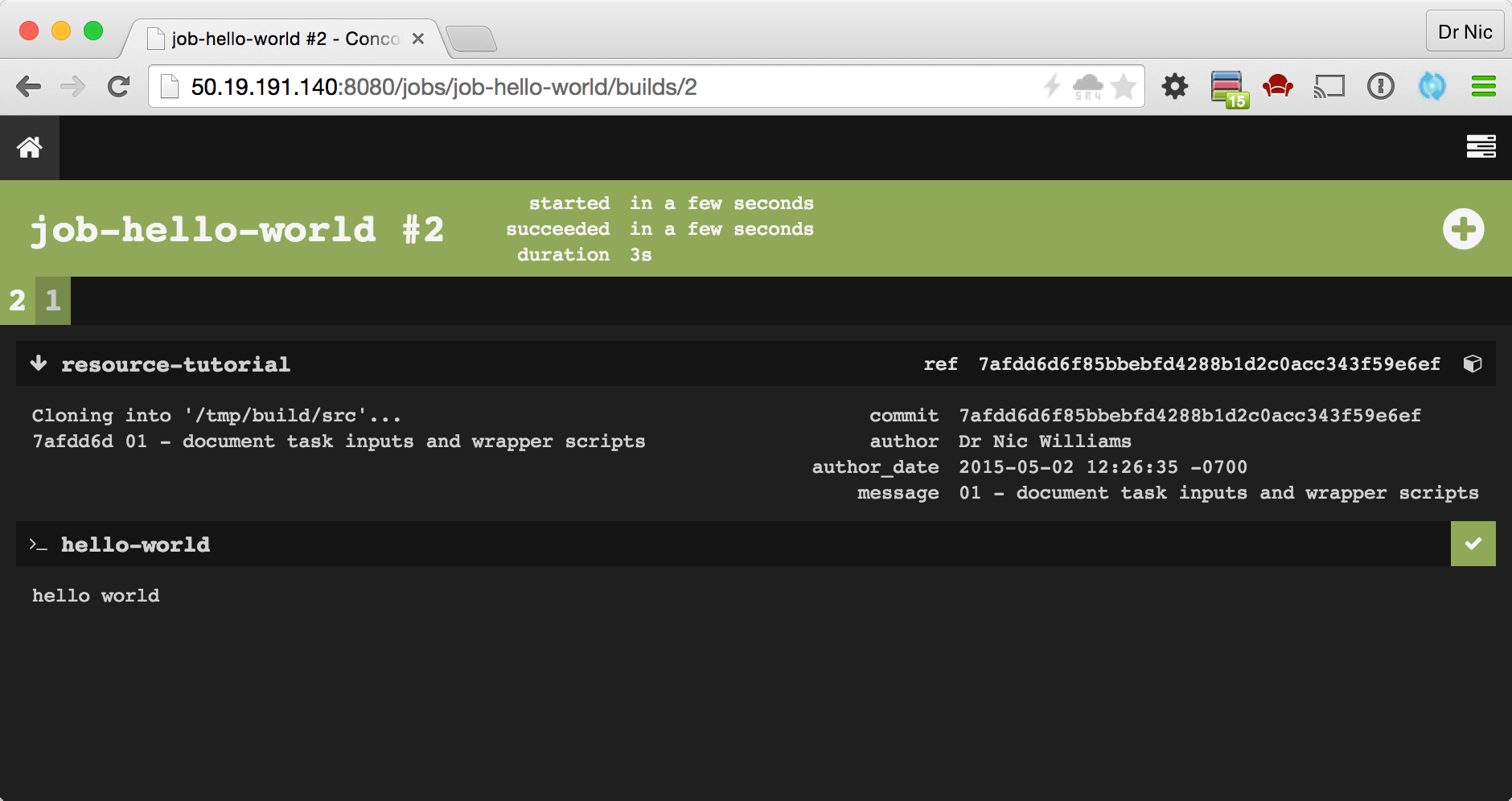
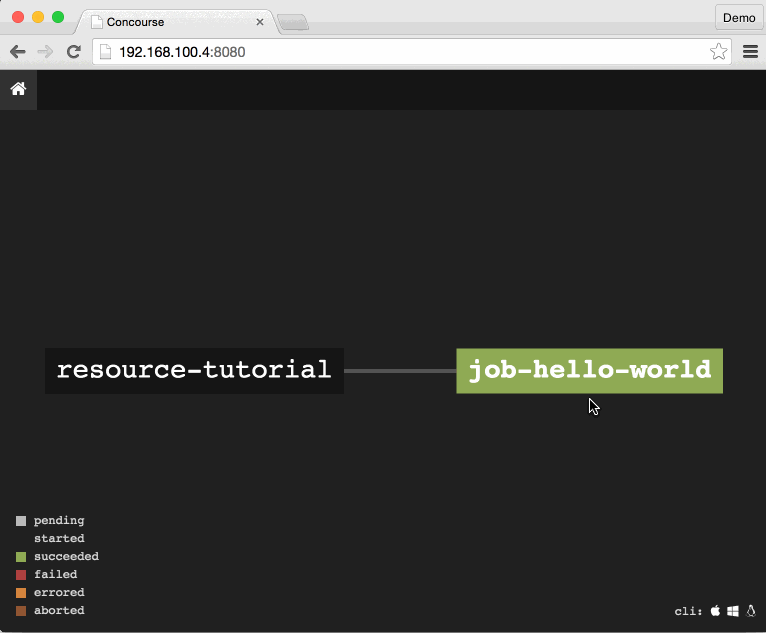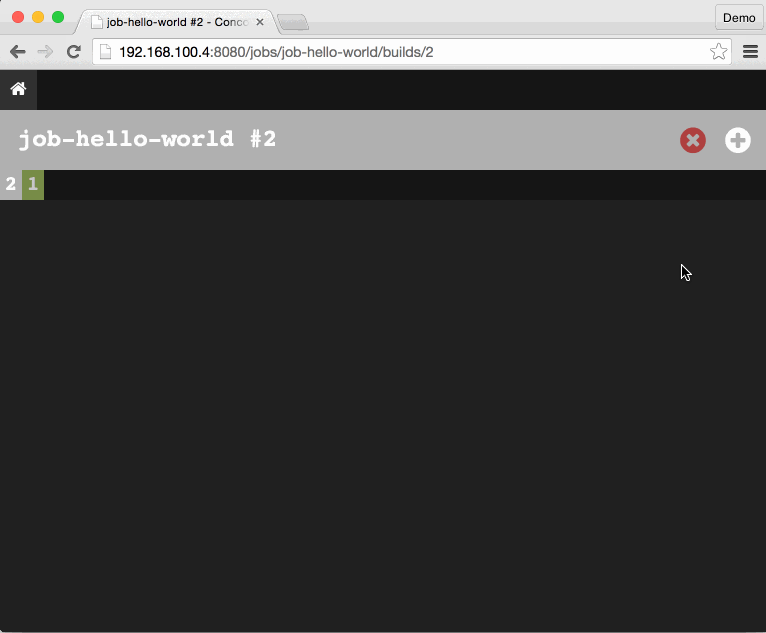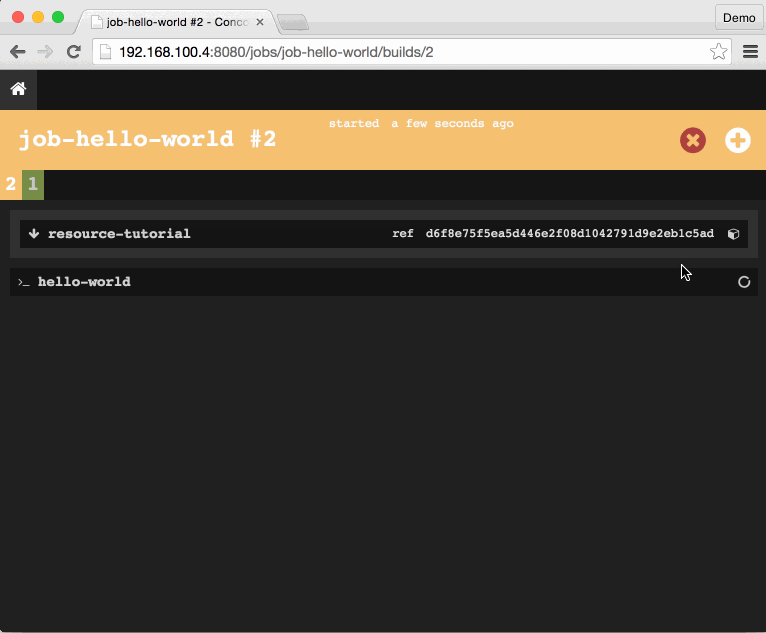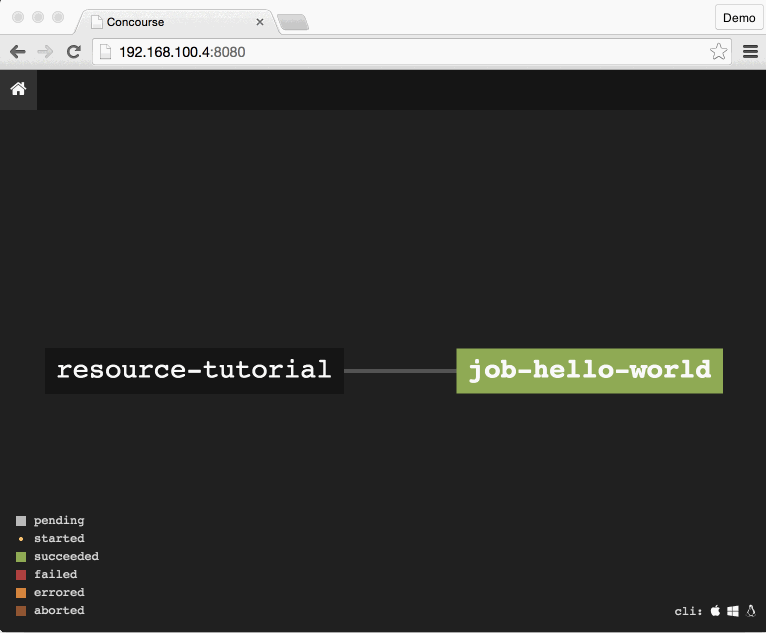
The in-progress or newly-completed job-hello-world job UI has three sections:
- Preparation for running the job - collecting inputs and dependencies
resource-tutorialresource is fetchedhello-worldtask is executed
The latter two are "steps" in the job's build plan. A build plan is a sequence of steps to execute. These steps may fetch down or update Resources, or execute Tasks.
The first build plan step fetches down (note the down arrow to the left) a git repository for these training materials and tutorials. The pipeline named this resource resource-tutorial and clones the repo into a directory with the same name. This means that later in the build-plan, we reference files relative to this folder.
The resource resource-tutorial is then used in the build plan for the job:
jobs:
- name: job-hello-world
public: true
plan:
- get: resource-tutorial
...
Any fetched resource can now be an input to any task in the job build plan. As discussed in lessons Task Inputs and Task Scripts task inputs can be used as task scripts.
The second step runs a user-defined task. The pipeline named the task hello-world. The task itself is not described in the pipeline. Instead it is described in a file tutorials/basic/task-hello-world/task_hello_world.yml from the resource-tutorial input.
The completed job looks like:
jobs:
- name: job-hello-world
public: true
plan:
- get: resource-tutorial
- task: hello-world
file: resource-tutorial/tutorials/basic/task-hello-world/task_hello_world.yml
The task {task: hello-world, file: resource-tutorial/...} has access to all fetched resources (and later, to the outputs from tasks).
The name of resources, and later the name of task outputs, determines the name used to access them by other tasks (and later, by updated resources).
So, hello-world can access anything from resource-tutorial (this tutorial's git repository) under the resource-tutorial/ path. Since the relative path of task_hello_world.yml task file inside this repo is tutorials/basic/task-hello-world/task_hello_world.yml, the task: hello-world references it by joining the two: file: resource-tutorial/tutorials/basic/task-hello-world/task_hello_world.yml
There is a benefit and a downside to abstracting tasks into YAML files outside of the pipeline.
One benefit is that the behavior of the task can be kept in sync with the primary input resource (for example, a software project with tasks for running tests, building binaries, etc).
One downside is that the pipeline.yml no longer explains exactly what commands will be invoked. Comprehension of pipeline behavior is potentially reduced.
But one benefit of extracting inline tasks into task files is that pipeline.yml files can get long and it can be hard to read and comprehend all the YAML. Instead, give tasks long names so that readers can understand what the purpose and expectation of the task is at a glance.
But one downside of extracting inline tasks into files is that fly set-pipeline is no longer the only step to updating a pipeline.
From now onwards, any change to your pipeline might require you to do one or both:
fly set-pipelineto update Concourse on a change to the job build plan and/or input/output resourcesgit commitandgit pushyour primary resource that contains the task files and task scripts
If a pipeline is not performing new behaviour then it might be you skipped one of the two steps above.
Due to the benefits vs downsides of the two approaches - inline task configuration vs YAML file task configuration - you will see both approaches used in this Concourse Tutorial and in the wider community of Concourse users.